【感想】 Adaptive Code のススメ

- 概要
- 知見
- サンプル
- 雑感
概要
今回は 「Adaptive Code C#実践開発手法 第2版」を読み終わったので、
そこで得た知見から特に感銘を受けた部分を3つ共有しようと思います。
Unity開発者なので、UnityとC#を題材にして紹介します。
本当は数か月前には読み終わってたんですが、記事にできていませんでした。。。復習の意味も込めて記事にします。
知見
リスコフの置換原則 (Liskov Substitution Principle) の保証
以下 LSP と呼称します。
LSPの概要
平たく言うと
"サブクラス、継承クラスはベースクラスに置き換え可能でなければならない"
というSOLID原則の1つですね。
本には「コントラクト(ルール定義)」として事前条件、事後条件、データ不変条件などといった重要な要素も紹介されています。
この本から得られたのは単なるリスコフの置換原則の知識ではなく、
「如何にしてリスコフの置換原則を保証するか」
という部分でした。
LSPの保証方法
結論を述べるとテストクラスを活用します
- ベースのテストクラスを定義
- 継承クラスのテストはベースのテストを継承
つまり、単に「LSPを満たすように実装する」だけではなく、
「LSPを機械的に保証する」をテストクラスで実現することになります。
LSP保証のテストクラスのサンプル
テスト対象のinterface
今回の題材は「数値の丸め処理を行うメソッド」とします。
以下の IRounder.Round の事前条件、事後条件をベースのテストクラスで定義しましょう。
public interface IRounder { float Round(float value, float interval); }
ルール定義
- 事前条件
- intervalに0は指定不可
- intervalに負の値は指定不可
- 事後条件
- 引数のvalueとintervalが同じ値の場合はintervalを返すこと
ベースのテストクラスを定義
ベースのテストクラスのポイントとして
- abstractクラスとして定義
- abstractメソッドとして生成メソッドを定義
- 継承クラスのインスタンス生成を定義可能にするため
- ルールを満たすことを確認するテストを定義
using NUnit.Framework; public abstract class TestRounderBase { // abstract指定により対象オブジェクトのインスタンス生成を継承テストクラスで定義 public abstract IRounder CreateTarget(); IRounder _target; [SetUp] public void SetUp() => _target = CreateTarget(); // 事前条件1: intervalに0は指定不可として、例外を出すこと [Test] public void Round_ThrowsExceptionIfIntervalIsZero() { Assert.Throws<RounderException>(() => { _target.Round(1f, interval: 0f); }); } // 事前条件2: intervalに負の値は指定不可として、例外を出すこと [Test] public void Round_ThrowsExceptionIfIntervalIsLessThanZero() { Assert.Throws<RounderException>(() => { _target.Round(1f, interval: -1f); }); } // 事後条件1: 引数のvalueとintervalが同じ値の場合はintervalを返すこと [Test] public void Round_ReturnsIntervalIfValueIsEqualToInterval() { Assert.AreEqual(1f, _target.Round(1f, interval: 1f)); Assert.AreEqual(2f, _target.Round(2f, interval: 2f)); Assert.AreEqual(10f, _target.Round(10f, interval: 10f)); } }
継承クラスのテストを作成
ベースクラスを継承したテストクラスを作成。
ベースクラスを継承して、継承クラスのインスタンス生成メソッドを定義する。
public class TestNearestRounder_LSP : TestRounderBase { public override IRounder CreateTarget() => new NearestRounder(); }
ちなみに NearestRounder の定義は以下です。
using System; public sealed class NearestRounder : IRounder { public float Round(float value, float interval) { if (interval <= 0f) { throw new RounderException("\"interval\" is 0 or less"); } return (float)Math.Round(value / interval) * interval; } }
テスト全体は TestNearestRounder.cs で確認できます。
また、こちらのサンプルには NearestRounder特有のテストも別クラスとして記載しています。
テストの実行
IRounderの継承クラスがLSPを満たしていることをUnitTestで確認。
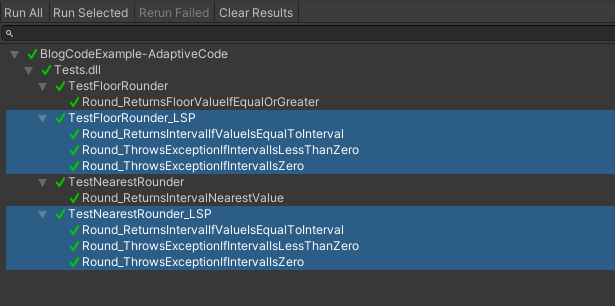
また、以後ルールを追加したい場合はベースクラスに追加することで、
継承クラスも常にルールを満たしていることが検証されるようになります。
LSPのまとめ
ベースとなるテストクラスでLSPのルールを定義することで、より強固なLSPを守るフローを構築することが可能になります。
interfaceのコメントに「intervalは0以上を必ず指定させること」などを記載してもプログラム上では何の影響もありませんが、 テストクラスを再利用することで保守する上でも保証することが可能になります。
abstractなテストクラスを利用する発想があまりなかったので、目からうろこでした。
投機的な一般化(Speculative Generality)
書籍には "投機的な一般化" と記載されていましたが文字だけだとなんのこっちゃ感がありますね(笑)。
原文は"Speculative Generality"です。
ちなみに書籍では「開放/ 閉鎖 の 原則」を意識するための要素として紹介されています。
投機的な一般化の概要
ここは私自身の解釈も含まれますが、端的に言えば
"あると良さそうと思って拡張可能に実装した、でも結局使わなかった"
的なことです。
interfaceを使った抽象化を身に着けたばかりのプログラマーによくある行動として、
「あらゆるものをinterface化して、意図しない拡張性を持たせてしまう」というものがり、これが投機的な一般化となる可能性があります。
「すべての設計は明確な意図をもって行うべき」との説明があり、
投機的な一般化はそれに反する行いのことです。
予想されるバリエーション
「予想されるバリエーション」とは「何が拡張できて、何が拡張できないのかを明確にすべきである」と説明があります。
投機的な一般化の対比となり、設計は「投機的な一般化」ではなく「予想されるバリエーション」となるようにするべきということになります。
投機的な一般化の問題
- 拡張ポイント特有の実装が無駄になってしまう
- interfaceで抽象化されたメソッドを使用する場合、そのメソッドのあらゆる結果の対策が必要となる
- 例: そのメソッドが異常系を返すパターン、例外を出すパターンなどの考慮が必要となり、結果的に開発コストが高くなる。
- 意図しない継承クラスが作成されてしまう可能性がある
- 継承クラスが作成された場合は継承クラス特有の考慮が必要になる
- アセンブリ(Unityにおけるasmdef)に継承クラスが分散し、むやみにinterfaceを変更できなくなる
投機的な一般化の回避例
修飾子(sealed, internalなど)を指定
修飾子はコンパイラが解釈する要素となります。
つまりクラスのルールをコンパイルレベルで定義することが可能になります。
- クラスに
sealedを指定し、派生クラスの作成を制限- もし派生クラスを想定していないのであれば基本的に
sealedを付けて保守範囲を限定する - 余談: C#はデフォルトで非
sealed(派生クラスの作成可能)
- もし派生クラスを想定していないのであれば基本的に
- クラスに
internalを指定し、異なるアセンブリでの派生クラス発生の回避internalクラスはアセンブリ内でのみアクセス可能なので、自分の管轄外での派生クラスの発生を回避できます- 余談、もしinternalクラスのUnitTestをしたい場合は InternalsVisibleToAttribute を活用すると良いです
ちなみにKotlinだとデフォルトでは派生不可(非open)で、僕がKotlinを好きな理由の1つだったりします。
プロダクトの拡張ポイントを見極める
ここはノウハウや経験に基づくものになります。
「投機的な一般化」は拡張部分に焦点を絞ったテーマのため少し話はずれてしまいますが、
以下のことを意識してみるとよいかもしれません。
- もし自身が企画者である場合は「この拡張が必要な理由が明確になっている」かを考慮する
- もし自身が実装する立場であった場合は、企画した人が「とりあえずあると良さそうな部分を提案する」といった性質がある場合は、そのアイデアを深堀して必要性を明確化する
「15分程度で終わる議論をせず、5日かけて実装したけどやっぱりいらなかった」みたいなことは極力避けましょう。
拡張ポイントを作るということは、それだけ保守範囲も増えるということを意識すると良いと思います。
投機的な一般化のまとめ
「すべての設計は明確な意図をもって行うべき」という言葉にはなかなか考えさせられるものがありました。
意図をしない部分があるということは、言ってしまえばあらゆることが起こってしまうと可能性を秘めているということです。
だからこそノウハウを蓄積して、予測できなかった事象を少しでも減らしていきましょう。
私もクラスを作るとき、派生を想定していない場合は sealed を忘れないようになど小さなところから意識するように心掛けていきたいです。
コナーセンス(Connascence)
コナーセンスの概要
コナーセンスとは「コードにおける依存度合(結合度)を図る指標」のことです。
依存関係の尺度を見極めるうえで意識すると役立つ概念となります。
コナーセンスにはレベルがあり、高いものほど処理との結合度が強いということになります。
コナーセンスの結合度
結合度を考える場合に簡単な判断として、
「ある要素を変更した際の影響度合い」と考えても良いと思います。
具体例を2つほど出します
名前のコナーセンス
"名前" のコナーセンスは、結合度が高いです。
ここでいう名前とは、クラス名やメソッド名など"コンパイラが解釈する名前"のことです。
注意として、メソッド名に使用されている単語自体の意味は関係ありません。
とあるメソッド名を変更したときは、そのクラスを使っていた部分も修正しないとコンパイルエラーが発生しますよね?
public float Calc() => ... public void Main() { var result = Calc(); ... }
上記のコードで、もし Calc() -> Calculate()とリネームした場合は、Main関数内も修正が必要になります。
クラス名やメソッド名は名前を変えると、それだけで使用者に影響を与えるため強い結合度を持っていると言えます。
値のコナーセンス
"値" のコナーセンスは、結合度が低いです。
これは身近ないい例があります。
よく「マジックナンバーは定数化しましょう」みたいなことを聞きませんか?
なぜ定数化するかというと、定数名に意味を込めて意図が伝わりやすいようにするためという側面もあります。
(もちろん、共通の定数を再利用するといった理由もあります)
public float CalcArea(float radius) => radius * radius * 3.141592f;
例えば上記のように3.14...とみると大体の人は「円周率だ!」となると思います。
しかし、すべての値がそれだけで意図が伝わるとは限りません。
public int CheckCode(int code) => code == 200 ? 0 : -1;
上記のコードは見慣れた人には「ああ、HTTPステータスかな?」となると思いますが、
見慣れない人には人には暗号のように見えると思います。
コードを書いた人は「HTTPステータスコードによってエラーコードを返すようにした」つもりで書いても、
第三者には伝わらりづらいコードになるかもしれませんので、以下のように定数名に意味を込めてあげましょう。
private const int HttpOk = 200; private const int ValidValue = 0; private const int InvalidValue = -1; public int CheckCode(int code) => code == HttpOk ? ValidValue : InvalidValue;
プログラム的にも 200 -> 100 に置き換えても別にコンパイルは通ってしまいますが、
それだと意図しない挙動になってしまいます。
値のコナーセンスのように結合度の低い場合は、定数化するなどの工夫が求められることが多いです。
コナーセンスのまとめ
コナーセンスはコード自体の品質を図るうえで非常に役立つ指標になります。
書籍には「インターフェイスのコナーセンス」という非公式なコナーセンスが紹介されています。
インターフェイスは継承するオブジェクトの必須要素やクライアントの依存部分を定義することが可能で、
意味を込めるうえでは非常に有用な要素といえます。
書籍を読むまではコナーセンスという単語自体は知りませんでしたが、
「interfaceで要素を定義する」などは意識していたこともあって、より具体的な概念として知ることができました。
コナーセンスの要素として10個ほど紹介されており、それぞれに特有の観点がありますので気になったら確認してみてください!
サンプル
LSPについてのサンプルコードは以下にあります。
雑感
今回は技術書の感想という形で記事にしてみました。
こんな1ページの記事では紹介しきれないぐらいたくさんの知見について記述されています。
何気にアジャイル開発やスクラムについても簡易的に紹介されていますので、
アーキテクチャやコーディングだけでなく、ワークフローについても勉強になる本だと思います。
SOLID原則をより深堀したい人にはとてもオススメなのでよかったら手に取ってみてください!
それでは~